Just in time design is about designing something just before the design is needed. Do it any later and it’ll be implemented without any design thought, do it too soon and the design could be miss-informed.
Premature Optimisation
This is an often cited sin of software creation. It’s really just a sub category of premature design. It may be hard to know if a certain algorithm needs optimisation until it’s used in production. The same can be said of software design. No matter how well a piece of software is designed, until it’s integrated and used it’s design can’t be validated. If lots of time or effort is wasted optimising code that doesn’t need it, how much time is wasted refactoring code that wasn’t given any design thought. Even worse is the time wasted refactoring and redesigning code that was designed too soon with limited information and incorrect assumptions.
How much to design and when?
Does this mean we should abandon all up front design and do it retrospective. Certainly not, design what can be seen of the problems complexity just before the work is to be started. There are other factors to consider when figuring out how much to design. If the problem is well understood and a known design has worked well for similar problems, then it’s predictable that applying the design pattern to the problem at hand and doing the work will be the end of it. However, if the problem is novel or complex then this is not the case. In this situation it’s best to design for what can be seen, what is known. Make some (hopefully educated) guesses about what can’t be seen and most importantly acknowledge that some guesses have been made. This means going back and re-evaluating the design after the work is finished. The process of creating the code and putting it in to use should reveal most if not all of the problems complexity that couldn’t be seen before work started.
Avoid wasting time on a bad implementation by designing for what can be seen of the problem, avoid wasting time on a bad design by not designing for what can’t be seen of the problem. Doing the design work just in time means being able to see more of the problem.
Waterfall Design, Iterative Implementation
As an industry we’ve acknowledged the problems of the Waterfall method of software creation and largely abandoned it. Unfortunately there is a tendency, even in an iterative software creation process, to still do too much design prematurely. People then stick to it even as more is learnt about the problem space that could inform a better design. Iterative software development is about iterating on the problem not an upfront design to the problem.

To some extent this can seem counter intuitive but there are benefits such as delivering some functionality sooner. The benefit in terms of design, is that what’s been learnt in previous iterations can be used for the design work in the next iteration. If the problem is to provide a means of transport that’s quicker than walking, a skateboard is a good place to start. What is learnt from using a skateboard will be really helpful in creating something better. Iterative design will generally take a little longer than designing up front but the end result will be a better solution to the problem.
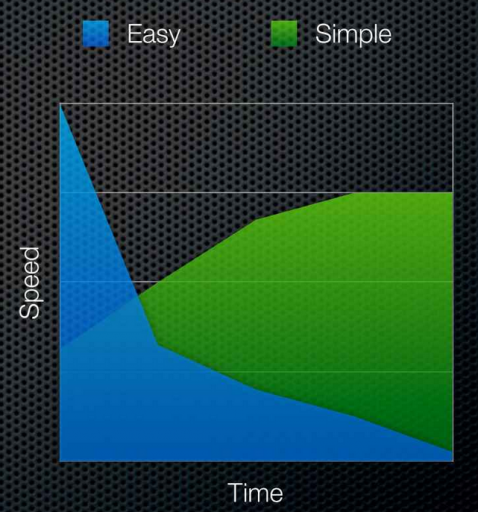 The trade off is that easy is very quick to get going with, “Hey look, I typed these commands in and now I have an app” but two months in to the project understanding the app will take more time than it should; “What’s this dependency for, do I have to use xml for my data?!”. The video I espouse above contains this diagram, it illustrates the point well. Simple tools, languages, frameworks etc… may be slower to get stuff done with initially but in the long run they will be faster as everything makes sense and the app isn’t getting bogged down in increasing complexity as time goes on.
The trade off is that easy is very quick to get going with, “Hey look, I typed these commands in and now I have an app” but two months in to the project understanding the app will take more time than it should; “What’s this dependency for, do I have to use xml for my data?!”. The video I espouse above contains this diagram, it illustrates the point well. Simple tools, languages, frameworks etc… may be slower to get stuff done with initially but in the long run they will be faster as everything makes sense and the app isn’t getting bogged down in increasing complexity as time goes on.